[導讀] 使用電子健康記錄(EHR)數據的預測建模預計將推動個人化醫療並提高醫療質量。 谷歌發布消息稱已經開源該協議緩衝區工具。 谷歌FHIR標準協議利用深度學習預測醫療事件發生
谷歌在arXiv上發表的一篇論文《Scalable and accurate deep learning for electronic health records》( Alvin Rajkomar et al.)。 文中他們提出基於快速醫療保健互操作性資源(FHIR)格式的患者EHR原始記錄表示,利用深度學習的方法,準確預測了多起醫療事件的發生。

論文摘要如下:
使用電子健康記錄(EHR)數據的預測建模預計將推動個人化醫療並提高醫療質量。 構建預測性統計模型通常需要從規範化的EHR數據中提取策略預測變量,這是一種勞動密集型過程,且放棄了患者記錄中絕大多數信息。 我們提出基於快速醫療保健互操作性資源(FHIR)格式的患者全部EHR原始記錄的表示。 我們證明使用這種表示方法的深度學習方法能夠準確預測來自多個中心的多個醫療事件,而無需特定地點的數據協調。 我們使用來自兩個美國學術醫療中心的去識別的EHR數據驗證了我們的方法,其中216,221位成年患者住院至少24小時。 在我們提出的序列格式中,這一塊EHR數據總計包含了46,864,534,945個數據點,包括臨床說明。 深度學習模型對預測院內死亡率(AUROC跨站點0.93-0.94),30天無計劃再入院率(AUROC 0.75-0.76),延長住院時間(AUROC 0.85-0.86)以及所有患者的最終診斷(頻率加權AUROC 0.90)等取得了極高的準確度。 在所有情況下,這些模型的表現都優於傳統的預測模型。 我們還介紹了一個神經網絡歸因係統的案例研究,該系統說明臨床醫生如何獲得預測的一些透明度。 我們相信,這種方法可以為各種臨床環境創建準確的、可擴展的預測,且附有在患者圖標中直接高亮證據的解釋。
在這項研究過程中,他們認為若想大規模的實現機器學習,則還需要對FHIR標準增加一個協議緩衝區工具,以便將大量數據序列化到磁盤以及允許分析大型數據集的表示形式。
昨天,谷歌發布消息稱已經開源該協議緩衝區工具。 下面為谷歌博文內容,小編編譯如下:
過去十年來,醫療保健的數據在很大程度上已經從紙質文件中轉變為數字化為電子健康記錄。 但是要想理解這些數據可能還存在一些關鍵性挑戰。
首先,在不同的供應商之間沒有共同的數據表示,每個供應商都在使用不同的方式來構建他們的數據;
其次,即使使用同一個供應商網站上的數據,可能也會有很大的不同,例如他們通常對相同的藥物使用多種代碼來表示;
第三,數據可能分佈在許多不同表格中,這些表格有些存在交集,有些包含著實驗數據,還有些包含著一些生命體徵。
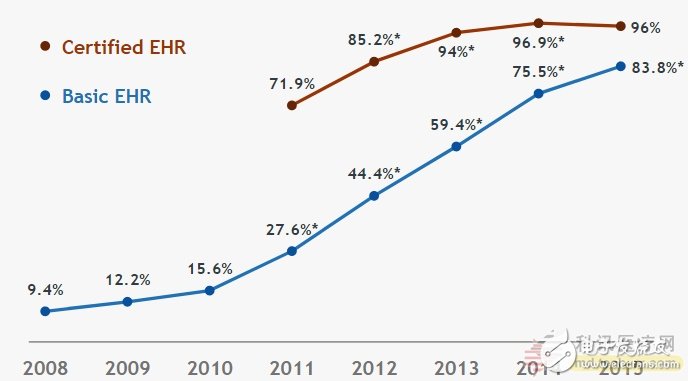
採用至少一個基本電子病歷系統並擁有經過認證的電子病歷系統的非聯邦急性護理醫院的百分比。 Basic的電子健康記錄( Electronic Health Record ,EHR)滿足EHR系統的基本功能,Cer TI fied EHR表示醫院已經與EHR有法律協議,但不等同於採用了EHR系統。
快速醫療保健互操作性資源(Fast Healthcare Interoperability Resources,FHIR)作為一項標準草案,描述的是用於交換電子病歷數據格式和數據元以及應用程序界面,該標準由醫療服務標準組織Health Level Seven Interna TI onal制定。 這項標準已經解決了這些挑戰中的大多數:它具有堅實的、可擴展的數據模型,建立在既定的Web標準之上,並且正在迅速成為個人記錄和批量數據訪問中事實上的標準。 但若想實現大規模機器學習,我們還需要對它做一些補充:使用多種編程語言的工具,作為將大量數據序列化到磁盤的有效方法以及允許分析大型數據集的表示形式。
今天,我們很高興開源了FHIR標準的協議緩衝區工具,該工具能夠解決以上這些問題。 當前的版本支持Java語言,隨後很快也將支持C++ 、Go和Python等語言。 另外,對於配置文件的支持以及幫助將遺留數據轉換為FHIR的工具也將很快推出。

關注電子發燒友微信
有趣有料的資訊及技術乾貨

下載發燒友APP
打造屬於您的人脈電子圈

關注發燒友課堂
鎖定最新課程活動及技術直播