以下內容為喬宇演講實錄:
我叫喬宇,來自中國科學院深圳先進技術研究院。 今天我想跟大家分享的是“給機器裝上慧眼,看懂世界。”

我們都有這樣的經歷,當我們去看一個幾個月的寶寶的時候,寶寶會情不自主地盯著我們,甚至沖我們笑一笑。 為什麼呢? 研究發現,即使是幾個月大的孩子,都具備識別人臉、判別人臉的能力。

當我們看到美麗的湖光山色時,我們可能情不自禁地感嘆自然的壯美,感覺心曠神怡、心情大好。

再看一張好像沒有趣味的圖片,大家能不能從這張圖片中看出來點什麼? 我給大家一點提示,圈裡面是不是好像有一條狗? 事實上,我們每個人都有一種與生俱來的視覺能力,就是通過眼睛去感知周圍的環境、欣賞美景,去閱讀書籍、理解世界。

眼睛和後面的視覺系統是我們人類最為複雜,也最為重要的器官之一。 人類獲得的70%的信息來自於眼睛,我們的眼底有上億個神經元的細胞用於感知、進行光電作用,人腦中涉及視覺信息處理的細胞達到數百億。 我研究的目的就是讓計算機像人一樣能夠看懂世界、理解世界。
計算機視覺是人工智能的核心領域之一,也被認為是推動當前社會發展、經濟進步的重要革命性技術。 它的應用領域非常廣泛,包括人臉識別、自動駕駛、安防監控、工業檢測、醫學影像、照片美化等等。
為什麼我們會關注計算機視覺技術? 事實上人類社會現在正在進入視覺信息的大數據時代,我們日常會使用微信,微信上每天上傳的圖片、分享的數頻達到數十億次。 另外一個很大的視覺信息來源是監控攝像頭。 據估計,在我們國家已經安裝了超過1.7億個攝像頭,每分每秒都會有大量數據的產生。

目前我們的系統已經可以實現很好的採集,因為攝像頭已經很便宜了,一個監控攝像頭幾百塊錢,裝在手機上的千萬像素級的攝像頭,大概只要幾美元。 也可以實現很好的存儲,即使用一個手機,我們也可以存儲幾千張甚至上萬張照片。 對於傳輸,我們現在用5G網絡,4G網絡都可以很好地看實時的視頻,5G網絡自然可以做到更好的傳輸。
現在技術最大的瓶頸就在於機器不能夠像人一樣去理解、識別圖像的內容,所以很多的視頻網站才需要雇用很多人來過濾一些不合法的視頻。 而對於監控視頻來講,一旦有案件發生,警察同志都要日夜兼程地閱覽大量監控視頻。
在這個背景下面,利用計算機視覺技術讓計算機能夠理解圖片、識別視頻就顯得尤為重要。 在這個背景下,我們科學院的前副院長譚鐵牛院士提出“圖像視頻、大數據是人工智能突破口,是信息產業的增長點。”
很多人就會問,理解圖片、視頻有什麼難的? 我們家小孩都可以做得很好,下面我就想通過一個三歲的小孩就可以做好的例子跟大家分享一下,為什麼讓計算機理解圖片非常難?

這個任務就是識別貓,給出一張圖片,我們判斷這張圖片中有沒有貓。 我們知道有各種類型的貓,有白貓、灰貓、黑貓。

貓可能站著、趴著、躺著,有些貓要跳,還有各種各樣可愛的動作。

圖片中可能還不止一隻貓,這些貓之間可能還有一些遮擋、交互。

很多小朋友會傾向於把這些也歸為貓,那對計算機來講,一張貓的圖片是什麼呢?
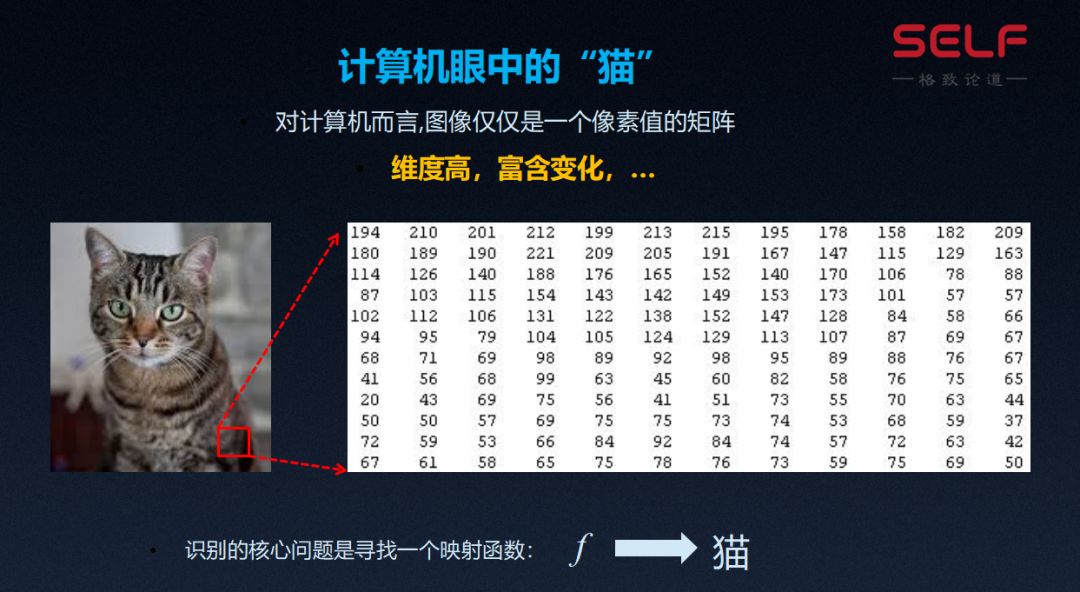
我們知道計算機是把圖片中每個像素的RGB,也就是紅、綠、藍三個通道的值存儲下來。 對計算機來講,一張圖片就是一個巨大的像素的矩陣,每個點的位置是這個點的色彩值。 那麼我們要解決的核心問題就是要找到一個映射函數,把一張圖片映射到貓的概念,這個問題的挑戰就在於我們輸入的維度很高,可能上千萬維,裡面又包含著色彩的變化 、姿態的變化、光照的變化、貓的數目的變化等等非常複雜的變化,這些就是我們要解決的挑戰。
最早人們在想怎麼教計算機識別貓的時候,覺得應該分析一下貓的皮毛應該有什麼紋理、什麼色彩,貓的眼睛是什麼顏色,貓的耳朵是什麼形狀,貓的鬍子多長,把這些總結 成規則,然後靠這些規則去判斷圖片中是否含有貓。
但事實上這些是非常困難的。 我們剛才看到了,貓的皮毛顏色有非常多的變化,貓的鬍子的長度可能可以比較準確地測量,但當圖片拍攝的遠近發生變化時,圖片中貓的鬍子的長度也會發生很大變化 。
後面我們就想,我們是怎麼教孩子識別貓的? 我們會不會在家裡對孩子說,你可記清楚了,鬍子這麼長的是貓,如果再長兩厘米,它就不是貓了。 我想沒有家長會這樣教,其實我們就是給孩子看了很多貓的照片,孩子就熟悉了貓的概念。

後來我們就把這個方法推廣到讓機器去學習貓的概念,這就是機器學習的方法。 我們會收集非常大量的關於一個物體的資料,這裡是關於貓的照片,然後我們把這些貓的照片放到計算機裡,用機器學習、統計學習或者是深度學習的模型,讓計算機不斷地分析、 理解這些圖片,然後識別貓的概念。
真的有人這麼做了,2012年,谷歌很興奮地宣布,他們發布了一個能夠識別貓的計算機算法。 他們從YouTube上收集了1000萬張圖片,然後用了16000個CPU的核,他們讓這16000個核反反复复地看這1000萬張圖像,看了一個星期的時間,最後他們很興奮地宣布 ,我們的計算機能夠識別貓了。

左邊給出的就是被這個算法判斷為貓的例子,其實仔細看就會發現裡面還是有些錯誤的,右邊是這些圖片的平均照片,確實這個算法識別出的大部分都像貓,也確實是貓 的照片。
當然作為一個計算機視覺的研究者,我所要做的絕對不是識別貓這麼簡單。 我們知道圖像中有各種各樣的物體,有人、車、建築物,有人造物體、自然界的物體,有動物、植物,這些都是我們識別的對象。

對於計算機視覺來講,我們還要應對的一個很大的挑戰,就是這些對像中包括非常複雜的變化,這種變化可能來自於光照、姿態,也可能來自於其它各種各樣形變的因素。 而且圖像、視頻的數據量很大,內容很豐富,這就要求我們的系統具有非常高的處理效率,這些就構成了技術者研究過程中的挑戰。

我經常用這幅圖來比喻我們的任務,這座山的頂峰是我們的目標,就是要建立和人類匹配,甚至超過人類的超級視覺能力。 我的目的就是登上這座山的頂峰,遺憾的是在很長的時間裡,比如在2011年,我感覺我只能在山腳到處尋找,離山頂非常之遠,那時候我們只能通過一些 方法很局部、很微弱地推動技術的進步。
當時我跟我的學生講,我們做計算機視覺的研究是非常安全的。 當然這個安全可能有一些貶義詞的部分,就是說有可能在我的有生之年,我們這個研究的很多問題都不會得到有效的解決。 我們今年提一個百分點,明年再招一個博士生,再提高兩個百分點,就這樣做下去,直到我退休。
這樣想想總是覺得有點落寞,事實上後面情況發生了很大的變化,一個重大的變化就是以卷積神經網絡為代表的深度學習方法引入到計算機視覺,我們終於找到了一條能夠快速登山的 爬山道,所以大家可以看到計算機視覺中的很多技術取得了日新月異的進步,在人臉識別、物體識別等任務上,計算機的能力在特定數據庫上甚至可以超越人。
爬到這兒的時候,我愈發地意識到這座山後面的部分可能更難爬。 爬山道在哪我們現在也不清楚,但作為一個研究者,我的職責就是從這看不清的雲霧中間去找到一條可行的道路來解決這些問題。 那麼下面我就分享爬山中間的一個工作,人臉識別和人臉檢測。
這項技術大家應該很熟悉,我們現在可以刷臉支付、刷臉解鎖手機,我們通過海關的時候也會有人臉識別的一些程序判斷是不是你本人。 這裡面大概可以分成兩個任務,一個任務是人臉識別,一個是人臉比對。 人臉比對的任務就是給出兩張照片,判斷是不是同一個人。 人臉識別就是給出一張照片,去判斷很多張照片中的哪張照片和這個照片是同一個人的。

很顯然,第一個任務更容易,1:1,隨便猜正確率也有50%。 如果第二個任務給出的照片是一千張,隨便猜是1/1000。 如果是整個上海2000萬人口的照片,那隨便猜的正確率是2000萬分之一。
人臉識別的流程是怎樣的呢? 我們會先把照片中人臉的區域找出來,這個工作叫做人臉檢測,就是發現人臉。 找到人臉之後,我們會通過一些計算機的算法,通過一些計算機的模型,比如深度學習的模型,去發現這些照片中與人臉相關的最有鑑別性的特徵。 比如說我們眼睛的形狀、鼻子的形狀,我們的臉型,臉部器官的組合都會成為有用的特徵。
通過計算機的算法提取這些特徵之後,我們會把這些特徵存起來,數據庫中的照片我們也會進行特徵的檢測和提取,最後我們把兩個特徵進行匹配。 比較像的,我們就認為照片中是同一個人,不像的就認為不是同一個人。
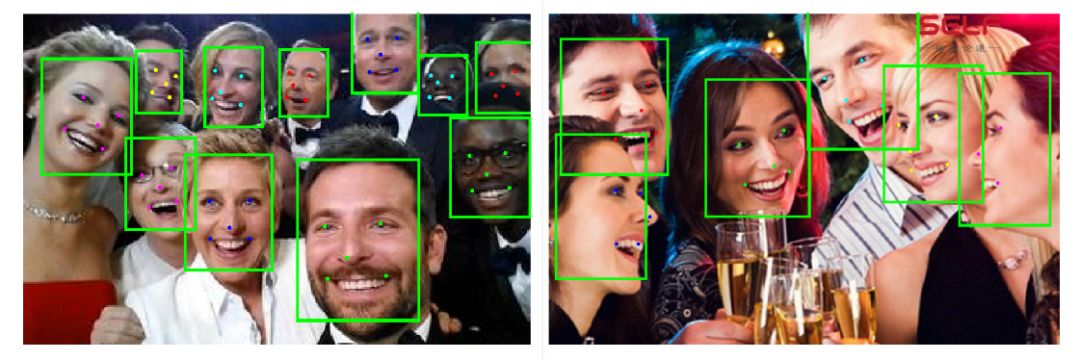
這是我們的算法在人臉檢測中所做的效果,我們可以看到現在的算法對於不同的膚色、不同的表情以及人臉姿態的變化,都有非常強的魯棒性。 我們的算法不僅能夠找到人臉,還能同時發現你的眼睛、鼻子、嘴角的位置。 可能有人會問,發現這個有什麼意義嗎?
其實蠻有意義的,我想很多女士都喜歡用美顏相機,其實在美顏相機做的第一件事情就是發現你的眼睛在什麼位置,鼻子在什麼位置,它會針對不同區域採用不同的 美化算法。 不然的話,我們把美白的方法用在眼睛上,就不好看了。

大家能不能猜一下,這張照片中有多少張人臉? 計算機發現了接近800張人臉,而且這件事情可以做得非常快,只需要不到一秒鐘的時間。 把照片送進計算機,它就會把人臉的數目和圈中人臉位置的框輸出出來。 找出人臉之後,我們就要進行人臉識別。

大家認為這兩張照片是不是同一個人呢? 回答是或者不是的都有,這其實是同一個人。

這兩張照片像不像同一個人呢? 好像是又好像不是,事實上這兩種照片不是同一個人。

那這兩張呢? 我看大家覺得不是的比較多,實際上這兩張是同一個人。
我們的人臉確實太多變了。 我現在40多歲,十多年前我剛好回國。 前段時間我在整理照片,把十多年前的照片整理出來,結果發現歲月真是一把殺豬刀,當然對女士除外。

這兩張大家應該都知道不是同一個人,但看起來確實蠻像的。

為什麼人臉識別具有挑戰性呢? 因為對於同一個人,隨著他的年齡、表情、包括妝容的變化,他的相貌都會發生很大的變化。 對於不同的人,地球上有六七十億的人口,即使在上海的2000萬人口中,你也很容易發現一個和你長的很相像的一個人。 這就是人臉識別的挑戰。 順便說一下,剛才我給大家看的這些照片,讓計算機去做識別,都沒有任何問題。

除了人自身的變化之外,還有一種情況,是有時候人臉的照片特別模糊,比如說我們照相的時候手抖動了,或者是離的比較遠,往往會有這樣模糊的照片。 可能這兩張照片大家頂多只能看出來是女性,看不清內容,我們就可以用計算機算法把它變得更清楚一點,就像右邊的這些照片。
現在人臉的識別技術到底到了一個什麼層次呢? 我剛才說過,人臉識別有兩個任務,一個是1:1的比對,一個是1:N的識別。 我們先看1:1的比對。 1:1的比對往往用在一些門禁和海關係統。 所以我們首先要保證的是,它一定不能讓一個人與照片不符時通關,比如說我拿著張三的身份證一定是不能通過的。 就是說在一個很大的數據集上,你的誤識率要非常低,然後再是識別的精度。

2014年的時候,我們可以做到10的4次方的數據集,也就是上萬人。 慢慢到10的5次方、10的6次方,到我們做這個實驗的時候,已經可以保證在千萬級的數據集上,達到99%的識別率。 這些有什麼意義? 我講一些應用場景來說明。
深圳灣和香港相鄰的地方有一個深圳灣口岸,是中國最大的單個的海關通關口岸之一,每天大概有6萬人通過。 在2014年的技術水平下,用這個技術,大概每三個小時會錯判一次,就是說每三個小時就可能有人用假證件混過去一次。 在2015年的技術水平下,每兩天會錯判一次。 到2016年的時候,可能一個月這個系統才會錯判一次。 到2018年,採用我們最新的技術,大概半年才會錯判一次。
所以大家聽完這次演講,要記住千萬不要帶假證件去闖海關,因為現在這個系統判錯的機率已經低於買彩票的中率了,與其去辦這樣的事情,不如多去買 兩張彩票。
剛才說了,1:N的識別更難,因為需要從N個人員中找出哪些照片是給定的這個人。 在2013年,我們可能在數百人中能識別出正確的給定對象,到2018年能夠達到這個數千萬人的層次,這背後實際上是技術快速的發展、方法快速的進步。
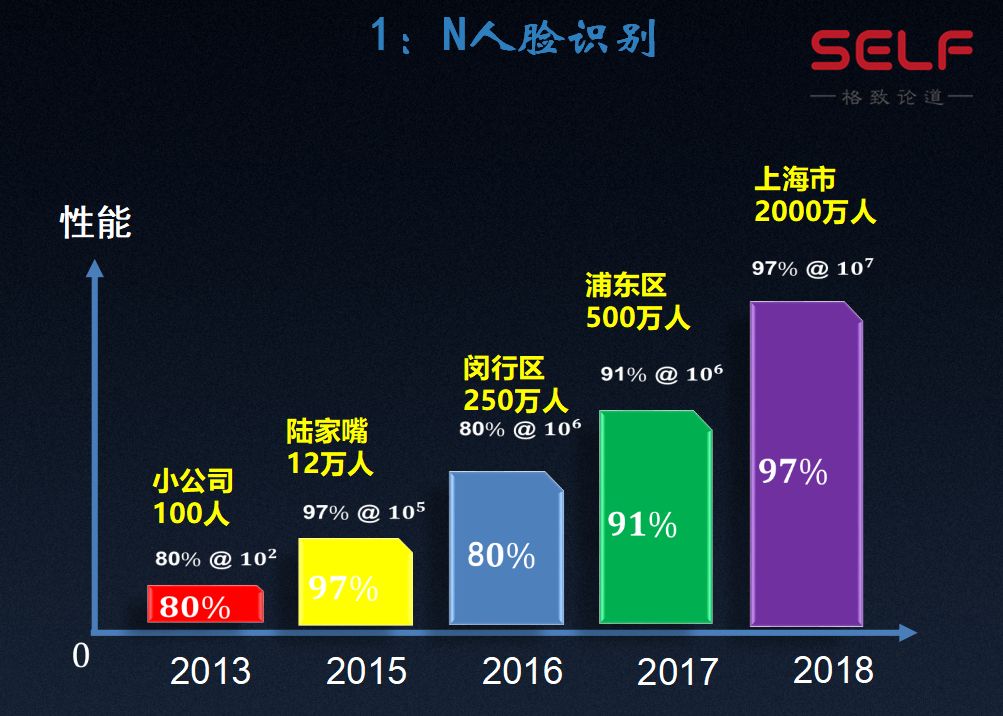
我們也可以體會一下這個技術的應用範圍。 2013年的時候,可能就應用在一個幾百人的小公司,每天員工打一次卡,可以保證沒有什麼錯誤。 到2015年,可以做到上萬人,比如上海的陸家嘴街道大概有十幾萬人的戶籍人口,在這個範圍內也有比較好的識別率。 到2016、2017年的時候,我們已經可以處理一個擁有幾百萬人口的比較大的區。
到2018年,我們最新的技術到達了千萬級別,我們知道上海大概有2000多萬人口,是中國乃至世界上最大的城市之一,這時候我給計算機一張照片,計算機就能從2000萬 人中找出來是誰。 可以想像一下,這個任務對人來講是幾乎沒有可能的,沒有人會認識上海市的2000萬人,更沒有人能宣稱自己可以記住上海市的2000萬張人臉。 但我們的計算機系統確實已經具備這樣的能力了。

我們的課題組在這裡面有很多些原創性的方法在國際上有最頂級的論文發表,也被大量的引用。 我們參加過一些國際競賽,MegaFace是美國華盛頓大學組織一個國際競賽,我們在FGNet跨年齡任務之上僅次於谷歌,排在第二位。 事實上谷歌用了2億的訓練數據,我們只有幾百萬。
同樣我們的技術也跟一些企業合作,像南京地鐵的大規模人臉識別,還有一些智能的服務攝像頭等應用。 除了人臉識別,我們還做很多事情,包括從視頻中去識別人的行為,在這件事情上,我們的很多技術也在像商湯科技這樣的大型企業得到了比較廣泛的應用。

我們還有一項技術是從場景中夠檢測和識別文字,大家現在經常去海外,去美國、英國可能還好一點,比如說去俄羅斯或者是韓國,可能我們會看不懂路牌、看不懂菜單 ,這時候你只要拿手機拍一下,它就會自動把這些文字檢測識別,並翻譯出來。 實際上在這項技術上我們也達成了與華為合作,已經應用到了華為的下一代智能手機中去。
我們還與醫院合作,做青光眼的輔助診斷的識別。 我們還把這些技術應用到了水下,讓水下的圖像變得更清晰,讓計算機能夠識別水下的浮游生物、魚等對象。 我們課題組做了很多成果,如果大家有興趣,可以去我們的主頁看一下。
在過去的幾年裡,我們也參加了計算機視覺領域的一些知名的國際競賽,取得了多次第一,為此我們的學生也付出了巨大的努力。 我想在這個領域,我們中國確確實實是在世界第一集團,我們和世界最領先的技術並沒有有明顯的差距。 這也是我們中國現在要重視發展人工智能技術的一個重要的原因。

作為一個科學院的課題組,我們做這些技術主要是為了服務大眾,所以我把我們費了很大力氣做出來的,我們的模型和代碼無償在網上進行了開源,每個公司或個人,只要感 興趣都可以來用我們的代碼,如果大家有興趣,可以掃一下這個二維碼獲得下載的地址,謝謝大家。

本文由 SELF格致論道講壇 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文請於文首標明作者姓名,保持文章完整性(包括虎嗅注及其餘作者身份信息),並請附上出處(虎嗅網)及本頁鏈接。 原文鏈接:https://www.huxiu.com/article/266489.html
未按照規範轉載者,虎嗅保留追究相應責任的權利