基因測序行業在近二十年的時間裡,發生了巨大的變化,其中一個最讓人吃驚的變化是它的測序成本大幅下降。 2001年,人類基因組完成測序,耗資高達30億美元,而現在成本降至1000美元,隨著時間的推移,甚至有可能降低到100美元以下。
如此幅度的成本下降,意味著大規模人群採用的條件已經初步具備。 那問題來了,就算是價格普通人可以負擔,但對於人們來說,為什麼要去做基因測序? 目前看 有幾個好處 : 一 是便於更好做疾病診斷; 二 是做疾病的提前預防,通過基因測序發現患某些病的概率較高,可以提前採取措施。 如好萊塢明星安吉麗娜·朱莉進行基因測序之後,發現自己有易患乳腺癌的基因,因此採取措施提前切掉乳腺。 ; 三 是有助於創建個性化治療方案。
這是從普通個人來說的直接好處,從行業發展的角度,或者從整體人類利益的角度,如果通過某種方式,能實現把基因組數據共享給研究者,這對研究人員找出規律,提供 個性化保健方案、治療方案或研發新藥等都有幫助。
如果實現了基因組數據共享,這裡有機會誕生一個數十億美金以上的基因組數據市場。 不管是基因組數據的所有者、還是基因組數據的需求方,都會從中獲益。
那麼,如何來創建基因測序的交易市場? 它需要解決哪些問題才有機會真正創建? 這就是本文試圖闡述的地方。
本文以Nebula Genomics為案例進行闡述。 這也是藍狐筆記最近關注的一個試圖通過借助區塊鏈技術和模式來創造基因測序市場的案例。
Nebula Genomics:創造基因測序市場的夢想
Nebula Genomics為了推動基因測序行業的發展,試圖在多個方面進行探索。
首先是Nebula Genomics要繼續推動基因測序成本的顯著降低, 唯有如此,才能讓更多普通老百姓參與進來,參與的人越多,意味著基因組的數據越多。
其次, 大多數人對新事物,尤其是基因測序這樣涉及個人隱私和安全的事情會比較在意,也會有疑慮,如果不能解決普通人的擔憂,那麼,即使價格便宜,也會遇到走向主流人群採用 的障礙,所以, Nebula Genomics會優先考慮提高基因組數據的安全和保護。
最後,這個行業存在著基因組數據的明顯需求者。 但是,目前這些需求者能夠得到的基因組數據少之又少。 Nebula Genomics也希望讓基因組數據的買家能夠更有效率獲取更多的數據。
基於以上明晰的思路,Nebula Genomics試圖通過區塊鏈技術來解決問題,以一種去中心化、加密的方式來達成目標。
基因組數據交易市場為什麼有機會?
先來看看什麼是基因組數據。 藍狐筆記參考了相關基因組資料,先給大家簡要分享關於基因組數據的基本概念。
DNA是一種鏈狀分子,它編碼每個生物體藍圖。 DNA由四個構建塊組成,其鏈狀分子的長度可變。 DNA的構建區塊由字母表示,包括A、T、C、G。 細胞中發現的DNA總數稱之為它的基因組。 基因則是DNA的序列,它可以編碼蛋白質生產指令,是多功能的分子機器。 人類的基因組大約有64億個字母。 人類基因組中的大多數功能序列還是未知世界。
那麼,為什麼要對DNA進行測序?
科學家在研究過程中發現了DNA的功能和結構,他們試圖通過讀取更多的DNA序列,研究它們,找出規律。 前面也提到,一開始基因測序成本很高,幾乎不可能用於主流人群。 但,該領域的技術發展迅速。 新一代的測序機器可以實現對數億分子的並行讀取。 新技術的進步讓DNA測序成本極速下降。 另外,通過蛋白質編碼基因組區域的靶向測序也利於降低成本。
目前市面上也有不少的個人基因測序公司,比如Ancestry和23andMe公司。 兩家公司使用基於DNA微陣列的基因分型來實現基因檢測。 不過它不是對連續的DNA序列進行測序,而是以大致規律的間隔來識別單個字母。 它們採用的方法無法全面識別字母,它們目前產生的數據對於基因組數據擁有者和研究者來說,價值相對有限。
從全基因測序數據中,個人可以全面了解個人基因組成。 研究者也能在更多數據中,不斷更新迭代研究結果。 全基因測序數據對研究人員價值更大。 比如說,全基因測序是鑑定非編碼DNA變體的唯一方法。 在現實中,超過90%的臨床重要的DNA部分都落在非編碼區域。 這也意味著,全基因測序有可能是發現治療靶標的主要手段。 目前來看,測序模式對於微陣列的基因分型模式,有它的優點之處。 如果能在實踐中證明更有效,那麼,它在基因組市場上,會產生很重大的影響。
對於個人來說,好處是什麼?
前文也簡要提及了基因組測序對個人的可能潛在好處。 下面更詳細地闡述其好處。
地球上任何兩個人的基因組中有99.9%是相同的。 而剩餘的0.1%則決定了每個人的差異。 0.1%的差異中有超過400萬的基因變體,這些變體產生了人與人之間的不同,包括身體特徵、性格以及疾病傾向。
這也就是說,如果完成每個人的全基因測序,就可以找出每個人獨一無二的地方。 它可以為健康相關的事情做出最佳選擇,包括減肥、鍛煉、醫療、生育等。 如果一旦成為現實, 這意味著個性化的精確醫療保健時代成為可能,可以根據每個人的基因組特性,提前做好預防措施。
醫療處方上來看,FDA批准的藥物中,有超過7%的藥物會受基因變體的影響,導致一些患者會出現對藥物產生不良反應。 如果有了全基因測序,醫生可以向患者開出更合適的藥物和更合適的劑量。 比如有一種藥物叫warfarin,它是一種常用的血液稀釋藥物,但它可能會導致部分患者內部出血,這部分患者往往是攜帶了增強其血液稀釋效應的基因變體。
預防性治療來看,大約有2%的人在高度“可操作的”基因中攜帶早發性致病變異體。 這些基因跟存在治療的病理相關,可能改變個體的結果。 比如,BRCA1和BRCA2基因的突變會顯著增加乳腺癌和卵巢癌的風險。 從預防性的角度,它會建議具有這些基因變異的婦女經常接受篩查。
對於大多數人來說,基因變體中攜帶有致命性的變體不多,但仍有問題。 比如脂肪肝疾病影響了8000萬美國人,但它有時候很難被發現,超過50%的人口基因變異增加脂肪肝並發症的風險。
優生優育方面來說,兩位計劃生孩子的父母可以進行基因測序,以此發現他們生下來的孩子可能的健康情況 。 通過父母雙方遺傳的疾病相關的變體,導致後代的患病風險。 目前看,全世界的5%人口中患有遺傳性疾病,這些絕大多數病症都從上一輩遺傳來的。 這些都是可以通過全基因測序進行檢測。
減肥方面,目前已經發現基因變體會影響減肥策略的有效性。 這意味著,不同人有不同的有效減肥策略,可以根據不同人的基因變體制定個性化的減肥方案。
體育鍛煉方面,基因變體也與體育成績相關,包括耐力、肌肉量、運動受傷風險等。 比如,韌帶撕裂的風險跟膠原蛋白基因的變體相關,對於某些基因變體的人來說,拳擊等運動中的頭部擊打會顯著增加腦部疾病的風險。 這也意味著,不同的基因變體,對於不同人的運動機能影響是不同的。
這也就能理解,為什麼在運動場上,有些人可以長達十年以上的持續高水平,如足球場上的梅西,而還有些人則是玻璃體質,雖然天賦很高,但容易受傷。 其中部分原因也跟每個人的基因變體相關。 如果進行了基因變體的測序,一是可以測試個體有沒有持續的競技水平可能,二是也可以針對性的進行預防和改善。
最後一個是基因編輯方面。 基因工程首先要鑑定出導致身體特徵和疾病易感性的基因變體。 然後在此基礎上進行基因組的編輯。 比如,讓肌肉生長抑制素基因失去活力有可能可以治愈退化肌肉疾病。
從產業需求來看,產業為什麼有這麼強的動力來獲取基因組數據和表型數據?
研究人員和生物公司、製藥公司都受制於基因組數據缺乏、數據質量低、數據採集效率低、數據獲取成本高等因素影響。
基因組數據的可用性還很低。 原因是因為目前的數據樣太小,很少有人做過全基因組的測序。 如果沒有大的基因組數據集,就比較難建立基因變體和性狀之間的關聯性。 不僅是數據,還需要通過機器學習來研究,比如深度學習,通過大量的模型訓練,獲得真正有意義的結果。 目前看,基因組學領域還很難獲得AI學習所需的足夠數據量。
表型數據是指包括所有個人特徵在內的信息,也包括病史等。 表型數據和基因組數據一起用來鑑定基因變體和性狀之間的關聯。 但目前來看, 表型數據有幾個問題: 一是數據需求方對隨機數據集不感興趣,而對具有特定表型的個體數據集感興趣,而是數據購買者會從有某些表型特徵的個人中獲取數據。 其次,基因組數據的擁有者需要有意願來提供表型數據,沒有表型數據,只有基因組數據就沒多大作用。 最後,目前收集的表型數據質量不穩定,通過中間人收集存在問題。
從數據採集看,效率低下。 目前現狀是,製藥和生物技術公司從一些非營利或營利組織獲取基因組的數據。 但整個購買流程效率低下,很難滿足需求。 一是數據採購流程沒有自動化,需要簽訂合同、付款、傳輸數據等,這些人工勞動對數據採集來說,不夠高效。 二是,不同來源的基因組和表型數據通常採用不同的數據格式編碼,這讓標準化不同數據集變得非常耗時。 這些問題都是生物和製藥技術公司頭疼的問題。
基因組大數據還不是真正的大數據,很難用作機器學習,也不利於後續的研究發展。 據估計,目前人類完成基因測序的人口才100萬人,0.02%的人口都不到。 即便如此,由於單個人的基因測序通常會產生很大的數據量,大約能達到200千兆字節,必須使用計算密集型計算處理。 這意味著如果未來有上億人口進行基因測序的話,會面臨很大的挑戰。 一是需要大量的存儲空間來存儲基因組的數據;二是網絡傳輸的速度也會對數據共享造成困難;三是基因組大數據的處理和分析需要大量的算力支持。
Nebula網絡存在的目的就是要解決以上的問題。
Nebula模式重塑基因測序行業
Nebula模型跟傳統模式完全不同。 它試圖通過去中心化的模式來重塑基因測序行業,它構建的基因組數據交易市場,在數據掌控權、數據的隱私和安全保護、經濟體系、大數據的準備等方面都有自己的解決方案 。
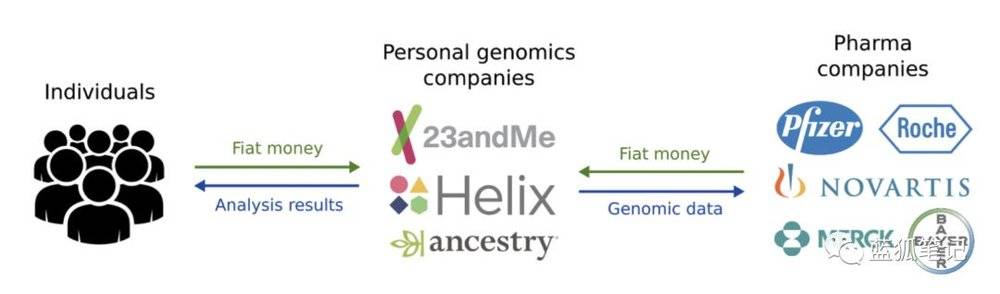
首先是數據的控制權和安全保護。
在傳統的基因測序行業的商業模式中,人們不僅給基因測序公司付費以獲取分析結果,同時,這些公司還會把這些基因組數據進行二次獲利,把它們賣給需要這些數據的製藥和生物 技術公司。
Nebula模式則不同,個人付費給測序服務提供者之後,測序的數據歸個人所有。 生物和製藥技術公司如果要獲得基因測序數據,必須向用戶購買,而不是向之前的測序公司購買。 這改變了基因測序數據的歸屬權問題。
同時基因測序數據還通過Nebula網絡獲得保護。 個人的數據由個人存儲,包括個人基因測序和表型數據。 數據所有人控制訪問的權限。 此外,Nebula還使用英特爾的軟件保護擴展和同態加密對共享數據進行加密和安全分析。
為了保護個人的隱私,在數據的買賣過程中,數據所有者是匿名的,而數據購買者必須是透明的。 所有的數據交易記錄都不可變地存儲在Nebula區塊鏈中。
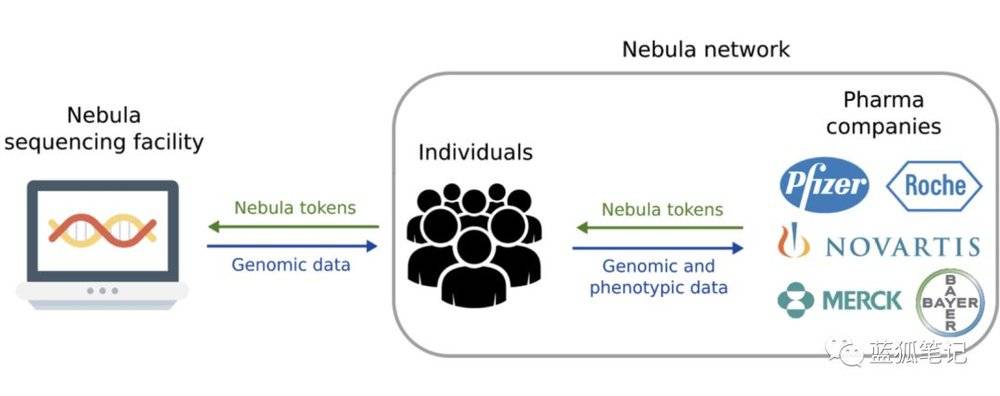
其次,token模式而非法幣模式。
在傳統的模式中,個人向基因測序公司支付法幣以獲得測序結果,生物和製藥技術公司也是向基因測序公司支付法幣以獲得研究數據。
而Nebula的token經濟模式中,形成了Nebula內部的一套經濟體系。
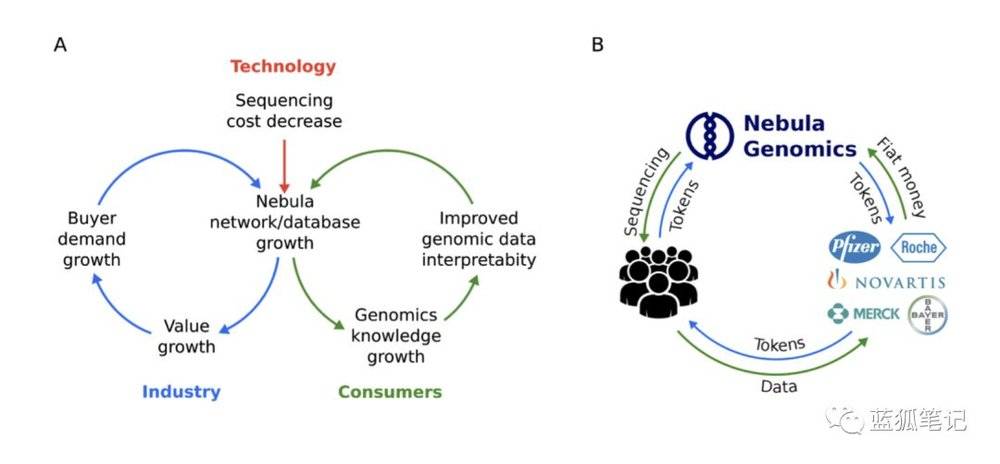
從上圖可以看到Nebula的token主要用於內部經濟體系的循環。 個人在Nebula測序的設施中獲得個人的基因測序服務,需要用Nebula 代幣支付,而生物和製藥技術公司也需要用Nebula代幣來購買基因組數據和表型數據。
從這個模型中,Nebula代幣的價值增長主要根源於整個Nebula網絡的增長。 它通過降低測序成本,吸引更多個體加入測序,而同時行業的需求也在增加,進一步降低測序成本。 而隨著基因組數據的增加,能夠給用戶帶來更多的好處,比如疾病預防、減肥、生育管理等,這會進一步提升對基因組數據和表型數據的需求。 而這個Nebula的經濟體系中,流通的是Nebula代幣,這個代幣的價值會隨著Nebula網絡整體價值的提升而增加。
再次,基因測序成本更低。
Nebula通過提供基因測序數據交易市場極大降低測序成本。 為什麼這麼說? 一是沒有基因測序數據的個人可以加入Nebula網絡支付token後獲得測序數據。 由於生物和製藥技術公司對有表型的個體感興趣,這樣,這些公司可以提供補貼,降低基因測序成本。 同時,隨著參與測序的機構越多,需求也越大,也許某一天,用戶可以免費獲得基因測序的服務。 同時,已有基因測序數據的用戶也可以通過加入Nebula網絡進行數據的售賣獲得收益。
第四,數據採集效率更高。
Nebula網絡通過基因測序市場推動用戶測序的意願。 尤其是它對用戶的疾病預防、減肥、優生優育等方面都有潛在的積極意義。 這導致用戶加入測序的意願大增。
同時,通過Nebula網絡還可以解決數據孤島的問題。 它通過去中心化的私有數據存儲方式來解決數據碎片化問題。 所有擁有基因組數據的個人或組織都可在Nebula網絡上提供數據,同時保留數據的所有權。
另外,數據需求方和提供者可以直接聯繫,能夠有針對性獲得高質量的表型數據。 基於Nebula的智能合約的調查工具可以幫助數據購買者更高效的獲取目標數據。 Nebula網絡會提供基因組和表型數據的標準格式。 最後,智能合約的有效應用,也會促進數據採購的加速,自動簽署合同,自動付款和傳輸數據,這都會讓比原來的人工過程高效很多。
最後,可為大數據爆發做好準備。
鑑於基因組數據非常龐大,通過讓數據所有者存儲自己的數據,解決了中心化數據存儲的問題。 Nebula計劃使用可用的邊緣網絡存儲空間。 此外,為了便於數據需求者計算基因組數據,Nebula還引入特定的數據編碼格式,也方便基因組數據在網絡上快速傳輸。 數據需求者可方便利用支持英特爾軟件保護擴展的任何計算硬件資源,他們可以在Nebula Genomics提供的計算節點、買家自己的節點或其他第三方節點上分析數據。
Nebula網絡:Blockstack平台與Nebula區塊鏈
Nebula網絡建立於Blockstack平台和以太坊驅動的Nebula區塊鏈上。 那麼,Nebula網絡由哪些節點組成? 它的基因組數據是怎麼來的? 基因組測序數據是怎麼處理的? 又是如何存儲的? 如何保證隱私和安全的? 測序數據和表型數據的交易記錄會記錄在哪裡? 它後續會不會把測序過程也實現去中心化?
這些問題都是構建真正可落地的基因組數據交易市場的重要問題。
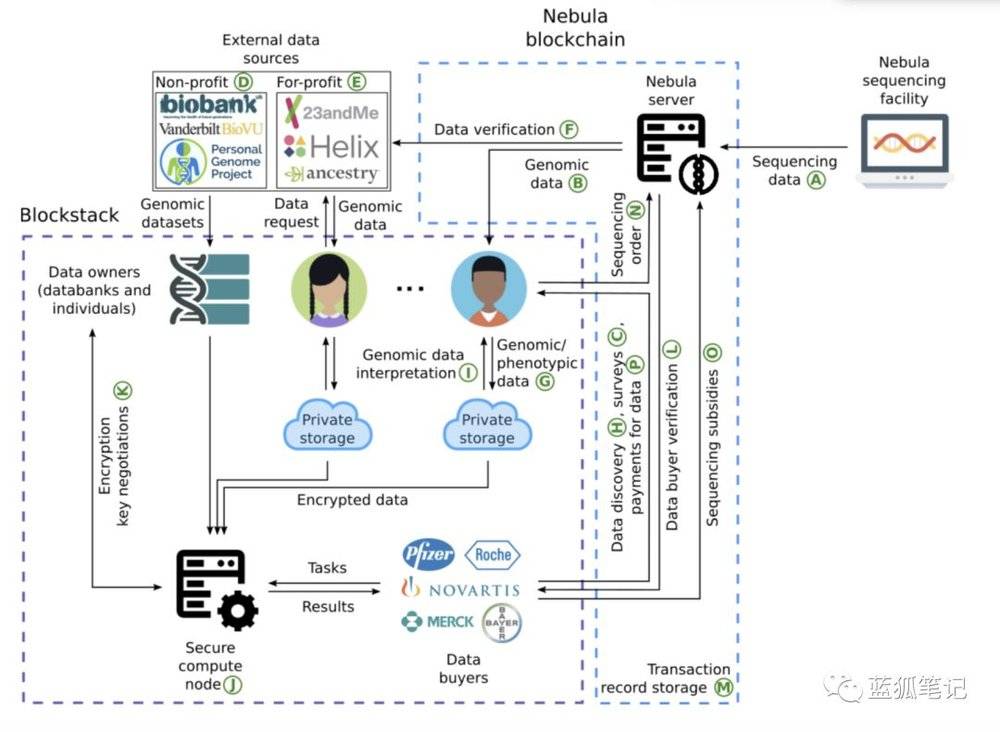
首先來看Nebula網絡的節點。
Nebula網絡包括數據所有者節點、數據購買者節點、安全計算節點、Nebula服務器。 數據所有者節點包括兩部分主體,一是想要共享基因組數據和表型數據的個人,二是擁有基因組數據庫的組織。
數據購買者節點一般是製藥和生物技術公司。 他們會使用Nebula代幣從數據所有者中購買基因組和表型數據,並分析安全計算節點上的數據。 完全計算節點運行Arvados生物信息開源平台以計算基因組數據。 安全計算節點可以由Nebula Genomics,數據購買者或其他第三方操作。
Nebula服務器處理主要是處理Nebula測序設施中生成的測序數據,同時驗證來自外部的基因組數據,驗證數據購買者的身份。
其次,Nebula網絡的基因組數據是怎麼來的?
Nebula測序設施預計使用下一代的DNA測序技術。 新一代測序技術會產生數十億的約250個字母的短讀數。 一個人的基因測序文件大概約10個測序讀數,大小達到150~200千兆字節左右。 Nebula Genomics計劃與Veritas Genetics合作測序。 通過與Veritas合作,Nebula Genomics可以符合監管,也不用擔負“得到認證的DNA測序設施”的相關運營成本。
除了使用Nebula測序設施產生的基因組數據,其他來源的數據也可以在Nebula網絡上出現。 比如數據所有人使用Nebula的工具將它的數據轉為基因組拼塊格式。 Nebula服務器會驗證數據的真實性。 數據所有者也需要提供真實性的證據。 另外,在Nebula網絡上提供基因組數據集的組織則需要Nebula Genomics的工作人員的驗證。 同時,數據所有者也可選擇在未經驗證情況下提供數據,由市場買家來決定是否願意為這一類數據付費。
除了基因組數據之外,為了發揮數據的作用,也需要表型數據的配合。 而表型數據的生成主要依賴於向數據所有者發布調查問卷。 通過調查問卷反饋提供該個體的症狀、處方藥物和診斷等。 Nebula也在參與跨數據庫的表型數據標準相關工作。
再 次,Nebula基因組數據是怎麼處理的?
當前在Nebula網絡上產生的測序數據將在Nebula服務器上處理。 首先將測序讀數參考人類基因組,對比後重建基因組序列,之後標識出基因變體。 同時,為了實現快速傳輸,變體的編碼列表需要考慮節省空間。 編碼方案還需要考慮支持有效計算,尤其是支持機器學習。 Nebula將採用基因組拼接的編碼方案。
基因組被分成重疊的可變長度序列,每個拼接塊都由所包含測序的哈希摘要代表。 所有拼塊位置中的拼塊變體都收集在拼塊庫中。 它們會隨著新基因測序和新變體的發展不斷增加。 個體基因組由測序的哈希數組代表。 這些哈希數組會轉移到數據所有者節點,之後可共享給數據的需求者。 這樣做的好處是可以實現快速的網絡傳輸,因為個體的基因組通過哈希數組來代表,大小只有10兆字節。
另外測序讀數文件也會傳輸給數據所有者節點,文件很大,約有150到200千兆字節,但只需從Nebula服務器傳輸過去,一次即可。 這些數據不會跟買家共享。 一旦文件傳輸完成,所有數據會從Nebula服務器中刪除。
第四,基因組數據和表型數據是怎麼存儲的?
數據存儲和訪問的控制會使用Blockstack平台,平台也可以構建去中心化應用。 Blockstack存儲系統允許用戶選擇自己的存儲提供商,比如Dropbox,並管理其對數據的訪問。
Blockstack也支持數據發現,可實現表型註冊表。 數據需求方可以查詢數據所有者節點,瀏覽過去的調查,識別參與過特定調查問卷的數據所有者。
由代表個人基因組的哈希數組引用的拼塊庫會存儲在公共的存儲中,比如IPFS或BitTorrent。 所有Nebula網絡上的節點都能夠訪問拼塊庫。 尤其是,計算節點進行數據分析時訪問拼塊庫。
第五,基因組數據如何實現安全計算的?
Nebula網絡目前使用Arvados生物信息開源平台來處理和管理基因組和表型數據。 這個平台主要是為基因組和其他大規模生物醫學數據設計,包括IBM Watson等在內的不少大型機構客戶也在使用。 同時,為了安全計算,Arvados在適用於安全計算節點上的英特爾軟件保護拓展區域內運行。
SGX是一組指令代碼,可以擴展英特爾x86架構,並允許專用內存區域的創建。 其中代碼和數據是隔離的,並受到外部處理的保護。 總之,英特爾軟件保護擴展允許不受信任的第三方對私有數據進行安全的遠程計算。 它實現了安全計算,同時這些計算比同態加密數據計算和安全多方計算的效率要高。
此外,通過將SGX與同態加密的混合,可以加速特定的計算。 在Nebula網絡中,數據所有者使用安全計算節點進行加密和共享個人基因組和表型數據。
不少生物信息計算的第一步是生成列聯表,包含基因組變體計數和相應表型。 列聯表計算僅需加法運算,可以使用加性同態加密方案執行計算。 首先,每個數據所有者節點使用加性同態加密方案加密值1或0,表示基因組變體存在或不存在。 之後,計算節點會對SGX專用內存區域之外的所有加密值求和。 加密的求和可以在SGX專用內存區域內進行解密,執行進一步計算。 因此,加性同態加密可以將解密數量減少至一個。
由於使用SGX有兩個主要缺點。 一是必須仔細設計軟件以實現在SGX 專用內存區域內部運行,同時不會把私有數據洩漏。 二是所有計算必須在英特爾CPU上執行,意味著計算不能用GPU加速。 但後續的機器學習,需要從GPU加速中獲益。
為解決這個問題,Nebula採用了SGX 專用內存區域和GPU加速計算中的數據保護混合方法。 數據會在SGX 專用內存區域中聚合和預處理,但是計算密集型的計算會在SGX 專用內存區域之外的GPU執行。 SGX 專用內存區域的預處理通過三種方式來保護數據的隱私。 一是所有數據完全匿名化,SGX預處理隱藏輸入數據的來源。 二是只聚合數據匯總,比如列聯表。 哈希數組編碼所有基因組,它們不會被暴露出來。 三是隨機噪聲會添加進入數據,以增強安全。
SGX-GPU混合模型的還有一個好處是Arvados的複雜性可以保持在SGX專用內存區域之外。 這會極大減少工程量。
第六,Nebula網絡提供賣家隱私保護
以太坊區塊鍊為數據所有者節點提供一定程度匿名保護。 網絡地址是加密標識符,與任何個人信息無關。 此外,對於買方需要進行驗證。 從基因組數據的所有者角度,他們都想知道自己的數據賣給了誰,他們是不是靠譜。 為了實現買家的透明,他們需要提供真實信息,並在法律上確定不能把數據分享給其他第三方。 這些認證工作由Nebula工作人員完成驗證。
第七,Nebula網絡的區塊鏈服務
Nebula基因組數據交易市場的所有交易記錄都會記錄在Nebula區塊鏈上,這是不可篡改的記錄。
Nebula將為合作夥伴提供測序設施,包括價格合理的全基因組測序服務。 該服務可以使用Nebula代幣支付。 同時,隨著DNA測序價格下降,還會變得更便宜。 另外,數據購買者也可以補貼個人的測序成本。
此外,Nebula調查工具會使用以太坊區塊鏈的智能合約,可以讓數據購買者創建高度定制化的調查。 比如可以向所有參與調查的人支付同樣的Nebula代幣獎勵,也可以根據不同的貢獻獎勵不同數量的代幣。
數據購買者也可以使用以太坊智能合約來購買個人基因組數據。 數據所有者收到代幣支付之後,他們的加密基因組數據會傳送到安全計算節點進行計算。 表型數據的購買也採用類似方式。
第八,基於Nebula網絡也會產生有價值的第三方應用
跟其他的中心化的應用程序平台不同,Nebula採用去中心化的模式來匯聚基因組數據。 基因組數據由個體用戶自己控制。
比如,數據所有者可以利用Nebula的基因變體解釋器進行個人基因組的數據解讀。 Nebula的變體解釋器是基於Blockstack的分佈式應用,在用戶本地數據上執行。 Nebula最初版本的變體解釋器是基於Veritas的變體解釋器。 這裡還有一個正向循環的好處。 隨著Nebula數據庫的增加,會發現更多基因和健康之間的關聯關係,這會讓Nebula的變體解釋器的表現越來越好。 由此吸引更多人加入到Nebula的網絡。 如果實現了這一點,這會成為一個自我增強的系統。
最後,Nebula對於測序本身也會採用去中心化模式嗎?
相比較於傳統模式,通過去中心化的數據存儲和安全計算,Nebula在基因組數據保護方面達成新的高度。 但是,數據的生成依然是在中心化的測序設施中發生。 如果測序設施的受到攻擊,基因組數據也有可能會被盜取。 要避免這種風險,唯一辦法是連測序本身也實現去中心化。
最理想的情況是,個人購買DNA測序機器自行測序,這樣就不用通過中心機構的測序設施來完成測序。 當然,目前看,還不現實。 因為當前的DNA測序儀器很大,很貴,價值可達100萬美元,也不易操作,普通用戶很難承受。
當然,技術也在發展,也許未來可能誕生手機一樣的DNA測序儀器,成本也能降至1000美元左右。 但是,這需要時間。 在過渡期內,Nebula Gemonics還會一直尋求最新技術,幫助個人實現可負擔的基因測序。 而最終的目標就是超去中心化的測序模式發展。
結語
傳統的基因測序模式很難建立起真正的基因組數據交易市場。 因為它很難解決基因組數據歸用戶所有的問題,無法調用用戶參與積極性,在獲取大規模數據方面存在天然的障礙。
而利用區塊鏈的去中心化模式,則帶來改變。 以Nebula為例,它首先把基因組數據的所有權歸還給個體。 其次,它構建了能夠保護用戶數據的安全計算。 再次,它充分利用智能合約、區塊鏈技術以及代幣體系。
這樣的結果是,Nebula的模式可以實現基因組數據的買家和賣家直接交易,跟傳統的模式不同,數據的買家和賣家之間的交易降低了成本。 成本的降低導致基因組測序服務價格更加便宜,推動更多人參與進來。 更多人參與進來,導致數據價值的提升,數據價值的提升能夠讓基因測序服務本身更有指導意義,包括對醫療、生育、減肥、保健等方面都重要的影響。
尤其是一旦實現了基因組測序數據、相應的表型數據與機器學習的結合,可能會給人類帶來很多意想不到的新發現,可以為每個人提供個性化的健康指導。 這對於大多數人來說,都具有足夠的吸引力。
此外,Nebula通過去中心化的模式也解決了人們對隱私保護的擔憂。 為了讓人們不用擔心,Nebula中的基因組數據擁有者可以私下存儲自己的基因組數據,同時控制訪問權限。 數據共享時,也會採用加密安全計算等技術。 與此同時,數據的擁有者會保持匿名,數據買家則要求是身份完全透明。 Nebula的區塊鏈存儲所有的交易記錄,這些交易記錄都不可篡改。
對於數據的需求方來說,通過從個體用戶直接獲取高質量的基因組數據和相應的表型數據,可以降低成本,更方便從數據中找出規律,便於研發新藥,便於為用戶提供個性化的 健康方案。
鑑於基因組測序目前的價格還不便宜,還有普通用戶在區塊鏈技術及相關技術的使用上還存在一定的易用性障礙,要形成真正的基因組測序交易市場還有很長的路要走 。 對此,我們要保持清醒的認識,同時也有充分的耐心。
從以上的闡述可以看到,區塊鏈技術和去中心化的模式能夠對基因組測序行業產生重塑的作用,期待像Nebula這樣的項目能夠充分利用區塊鏈,創建出真正的有規模效應的 去中心化的基因組數據交易市場。 一旦走向正向循環,這會產生前所未有的行業效應。
本文由 藍狐筆記 授權 虎嗅網 發表,並經虎嗅網編輯。 轉載此文請於文首標明作者姓名,保持文章完整性(包括虎嗅注及其餘作者身份信息),並請附上出處(虎嗅網)及本頁鏈接。 原文鏈接:https://www.huxiu.com/article/270600.html
未按照規範轉載者,虎嗅保留追究相應責任的權利